Creating a Text-based Résumé workflow
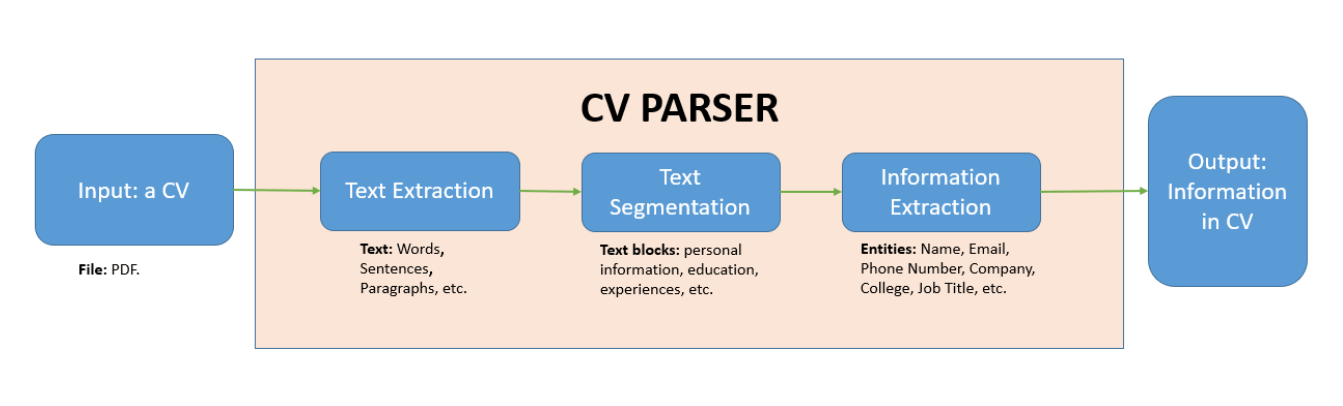 Image: a typical resume content extraction workflow from neurond.com
Image: a typical resume content extraction workflow from neurond.com
I used to keep my résumé (from here, “resume”) very up-to-date. For a long time, I had a resume crafted in #LaTeX because I have a long history with using that typesetting and markup language for purposes other than the ones most people think of, e.g. I wrote my college English papers in it, I had a slew of templates I created while I was a practicing attorney that would create letters, motions, and envelopes from source .tex files, etc. Keeping content in text makes it more portable across platforms and applications, and the nature of Microsoft Word is that you need to fully re-create the resume every couple years because some invisible formatting munges the entire document.
TL;DR I ended up using RenderCV as mentioned below in the [[Resume Workflow#RenderCV|RenderCV section]].
In the time since I last relied upon a resume, the method of applying for jobs –and more importantly, how recruiters review submissions– has changed pretty drastically. And despite all the great advances in technology over the past ten years, apparently, HR systems still are not that great at parsing a PDF or Word doc into text that can be machine-read by whatever algorithms and/or AI they’re using to perform the first pass. Because of this, you want to make sure to submit a machine-friendly description of your experience. There really should be a standard for all this stuff that makes it easy on both the applicant and the hiring manager. Like, I don’t know, some sort of HR standards body or something. A standard has never emerged, and I suspect that LinkedIn has a lot to do with that.
Additionally, having an easy way to keep one’s resume in sync and in multiple formats means that it can be quickly used for many purposes, from printing an attractive hard copy to piping it through some [[Fabric]] AI workflows. So this set me on a fairly long hunt for a system where I could write once, and generate in multiple formats.
The search for a resume workflow
First round
LaTeX & Pandoc
Since my resume was already in LaTeX, using the 20 second CV set of template –which I think is very nice– I went and updated that and then ran it through pandoc, which is a multi-format document converter. The results ended up being pretty poor and not useful. The PDF looked great, obviously, but pandoc did not understand the LaTeX very well and the Markdown required a lot of edits.
We want everything to look good upon compilation/export/save as/whatever, so this was not an option.
Interlude
I had kind of given up at this point, figuring I either needed to just go Google Docs or maintain a Markdown version and attempt to keep them in sync. Then, I came across a post about an auto-application bot and the author had a related project that used resume information formatted as YAML to create a specific resume based upon job description or LinkedIn post.
Resume from Job Description
This project is called resume render from job description (no cute animal names or obtuse references in this project!), and I gave it a try, but it appeared to require all the fields, including e.g. GPA. I don’t know about you, but I'm way past the point in my career where I'm putting my GPA on a resume, so it wasn’t that useful.
It was late on a Thursday night, so obviously it was time to look a bit further into the rabbit hole
Online options
I found a number of projects that were a service model where they host and render the resume for you. These included resume.lol (I question the naming choice here), Reactive resume (opensource, excellent domain name, and it has nice documentation), and WTF resume (my thought exactly!).
These all came from a post of 14 Open-source Free Resume Builder and CV Generator Apps.
JSONResume
As I traveled further down the Internet search rabbit hole, I came across JSON Resume, an #opensource project with a hosting component where people craft their resumes in JSON and it can then render in a number of formats either via a command-line tool or within their hosted service, making it a kind of hybrid option.
At this point, I felt like I was almost there, but it wasn’t exactly what I wanted. JSONResume is very focused around being part of their ecosystem and publishing within their hosting ecosystem. The original #CLI tool is no longer maintained, and a new one is being worked on, which appears minimal but sufficient for the task. A nice thing is that they have some add-ons and have created a sort of ecosystem of tools. Looking over the project’s 10 year history, those tools have a tendency to come and go, but such is the nature of OSS.
The Award for “Project Most Suited to My Workflow” goes to….
Another great thing about JSON Resume is that they, i.e. Thomas Davis, have done a fantastic job of cataloging various resume systems out there in their JSON Resume projects section. There is so much interesting stuff here –and a lot of duplicative effort ahem see the “HR Standards” comment above– that you can spend a couple days looking for the project that best fits your needs. For me, I landed on RenderCV, which is not only in the bibliography, but also mentioned on the Getting Started page because there are tools to leverage JSON Resume from RenderCV!
So without further ado…
RenderCV
While RenderCV is a part of the JSON Resume ecosystem, in that people have created scripts to convert from the latter to the former, it is a completely separate and standalone project. Written in #python and installable via pip. RenderCV’s approach is to leverage a YAML file, and from that generate consistent resumes in PDF, HTTML, Markdown, and even individual PNG files, allowing the applicant to meet whatever arcane requirements the prospective employer has.
graph LR
YAML --> TeX & Markdown
TeX --> PDF & HTML & PNG
Resume generation workflow
Using RenderCV
Getting started with RenderCV is like pretty much any other project built in python
- Create a virtual environment using
venvorconda, e.g.conda create -n renderCV python=3.12.4 - Install via pip with a simple command
pip install rendercv - Follow the quick start guide and create a YAML file with your information in it
- Run
rendercv render <my_cv>.yaml - View the lovely rendered résumé
Extending RenderCV
This was great, as I now have a very easy-to-edit source document for my résumé and can quickly create others. I’m hoping Sina, the author, makes the framework a bit more extensible in the future because the current templates are oriented toward people with STEM backgrounds looking for individual contributor roles. However, as some of us move further in our careers, the résumé should be less about skills and projects, but more about responsibilities and accomplishments as we lead teams. I have enhanced the “classic” and “sb2nov” themes so that they take these keywords as subsections to a specific company/role combination under the professional_experience section.
Theme update for Leaders and Managers
I created a fork which contains updates to v1.14, adding the “Responsibilities” and “Accomplishments” subsections for company: under the Experience section.
This allows leaders to craft their resume or CV in such a way that it highlights the breadth of their influence and impact to the organization.
The following themes support the additional subsections: – markdown – classic – sb2nov
A non-updated theme will simply ignore the content under these subsections; omitting these sections will make the resume look like the original theme.
Hopefully the framework will be more extensible in the future and I can add this as a pull request.
In the meantime, the forked repo at https://github.com/ktneely/rendercv4leaders should work on its own, or the /ExperienceEntry.j2.tex and /ExperienceEntry.j2.md files from those themes can simply be copied over the existing.
How to use
Usage is extremely straightforward, as this merely extends the framework with a couple new keywords for the Experience section and looking for a preceding company declaration. Here is an example:
professional_experience:
- company: NASA
position: Director of Flight Operations
location: Houston, TX
start_date: 1957-03
end_date: 1964-06
responsibilities:
- Manage the Control room.
- Write performance reports.
- Smoke copious amounts of cigarettes
accomplishments:
- 100% staff retention over the course of 9 rocket launches.
- Mobilized and orchestrated multiple teams to rescue astronauts trapped in space.
- Lung cancer.
This will then render “responsibilities” and “accomplishments” as italicized sections under the job role, highlighting what a difference made while performing in that role.
Maintaining Multiple Versions
This is basically what it all comes down to: the ability to maintain different versions for your target companies. While some work is being done to modularize the source content, it is not yet to the point where each section of the resume is a building block that can be invoked at compile time. What I do is maintain different YAML files and use the parameters in the rendercv_settings section to direct the output to different, meaningfully-named directories while maintaining a generic name for the file itself.
So, instead of “Kevin-LargeCorprole.pdf”, “Kevin-Startuprole.pdf”, etc., I simply send “Kevin-CV.pdf”. This way, it’s not incredibly obvious to the reviewer that I have specially-crafted a resume for that job, it just happens to look like I have exactly what they’re looking for in my default resume.
Automation
Want to automate the build of your resume whenever you update the source file(s)? Look no further than rendercv pipeline to generate the output whenever you commit source to GitHub.
Also, since version 1.15, the --watch flag will watch the source file locally and re-compile every time you save the source YAML file.
References and further exploration
- Neurond.com blog post: What is a CV/Resume Parser and How Does it Work?, Trinh Nguyen, Aug 16, 2022.
- TeXMaker: an Open-source TeX editor
- RenderCV user guide
 image 1: Tier 1 go bag – The Weekender with a backup battery, USB-C to USB-C cable, USB-A to micro-USB cable, and USB-C adapter. Small, ready to go, and easy to drop into any bag.
image 1: Tier 1 go bag – The Weekender with a backup battery, USB-C to USB-C cable, USB-A to micro-USB cable, and USB-C adapter. Small, ready to go, and easy to drop into any bag. Image 2: Zipped Weekender Go-bag and its contents in detail
Image 2: Zipped Weekender Go-bag and its contents in detail