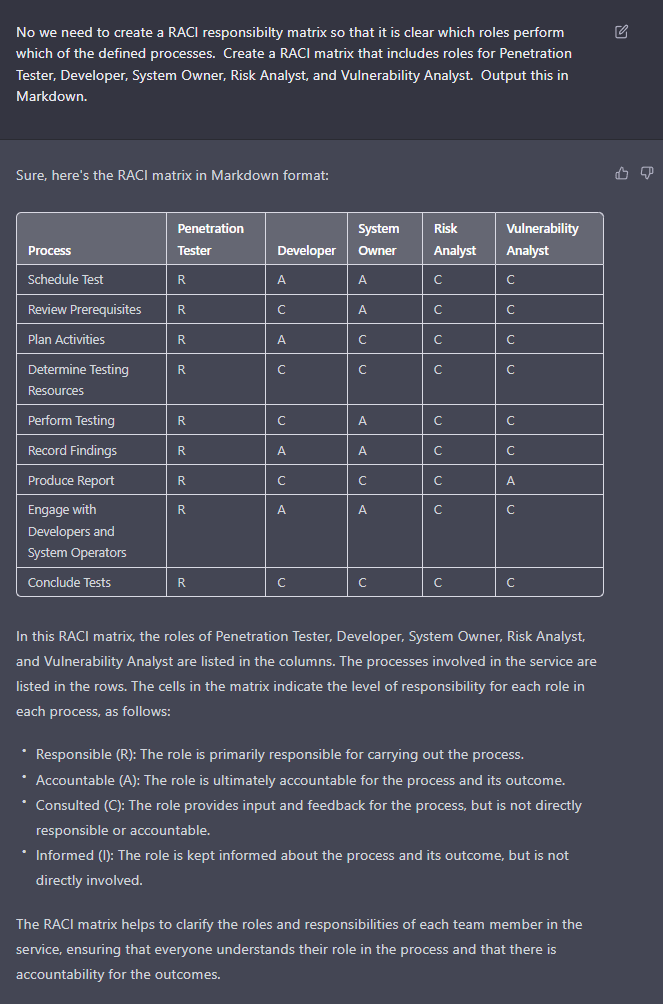
Using an eGPU to provide critical processing for AI research (and games) – Part 2: Implementation
Finishing the POC
I ended part one with a working configuration, I proceeded to test some scenarios to make sure things were working correctly. For the most part, I connected the keyboard and mouse to the NUC through an old USB hub and directly connected the Ethernet cable to the NUC. The Thunderbolt cable connects the NUC to the #eGPU and the monitor is connected directly to the Nvidia card. As my testing progressed over the next couple of days, I was mostly happy with the results, but I also ran into a number of quirks and one really unlikely hardware malfunction.
My (Eventual) Build
I paired the Razer Core X Chrome with a recent (late 2020) Intel NUC I chose this one because they had great compattibility results in most of the articles I was reading, and I liked the USB hub and ethernet portt in the back of the device. In retrospect, I probably would have been better off with the plain Razer Core X. The hub’s functionality has been flaky in my experience, sometimes working with the Ubuntu NUC,
Testing and Troubleshooting
NUC & eGPU experience
I encountered a few quirks during the proof-of-concept phase. For whatever reason, the NUC does not fully recognize the eGPU on every startup. This manifests in two ways described below
No login screen after boot
Sometimes, the display would update only as far as the startup messages, ending with checking the volume inodes. Moving the HDMI cable from the eGPU enclosure to the NUC itself showed the login screen once, but most often, it was impossible to login locally. I could either SSH in and reboot it or just long-press the power and turn back on.
System not actually using the GPU
The most common problem, and similar to the above, sometimes the system would startup, but immediately upon using the GUI, I could feel that something wasn’t right. The password echo dots took just a few parts of a second too long to appear. Dragging windows around was a choppy experience. Even though running nvidia-smi showed the card as recognized, it was clear that it was not being used as no processes had been assigned VRAM.
Every single time, a reboot fixes this issue. The way to prevent it is to not turn off the eGPU enclosure at night and leave it connected. However, the enclosure’s fan will run continuously and the lighting glows if one does this and that seems like a waste.
NUC power switch
Completely unrelated to the actual configuration and testing, but impacting the POC nonetheless was the power switch on my NUC going out. After a frustrating day of testing, I set everything aside -even unplugging all the cables- to give myself a break. Coming back the next morning with some fresh ideas, the NUC wouldn’t power on. I could see that it was receiving power (there’s an internal LED), but pressing the button did nothing.
Apparently, this is a common problem with NUC devices. Luckily, I was well within my three year warranty, so I opened a support ticket. I had found the likely fix online: resetting the CMOS, however, I could not unscrew the screws affixing the motherboard to the chasis. So, I opened a ticket, the agent said the same thing, but eventually I was able to RMA it. I have to say, Intel’s support team was great here.
Windows & eGPU experience
I haven’t yet upgraded my laptop or any other Windows system to something with Thunderbolt 3, so this is planned for the future.
Day to day experience
So far, the games have worked okay. That is to say that on an older NUC with a lower CPU (it’s purpose was mostly to have decent memory for many low-impact #Docker containers, and sufficient high-speed storage for database seeks) has been pretty good. This is my “workhose” system: something I expect to use for long-running, non-interactive jobs, and it seems to do them excellently. When the system
Games
Just as I started in on this project, I was also listening to the [Linux Downtime](https://linuxdowntime.com podcast, and as luck would have it, they had an episode with Liam, the author of the Gaming on Linux website, They introduced me to Proton, a Steam project to bring mainstream games to #Linux, requiring just a right-click setting to enable on Linux what would otherwise be a Windows-only game. This opened up a realm of possibilities, and also delayed the testing as I played through thoroughly tested the capabilities of the NUC + eGPU combination.
Running games under Ubuntu with the eGPU connected seemed to work well. The window on the enclosure is nice, as you can visibly see when the system offloads to the GPU
Intel NUC with Razer Core X Chroma
Deployment
Before and After

Considerations
With the newest GPUs, space is a consideration. Some of the most powerful are three PCIe slots wide, and the Chroma enclosure only handles 2 slots (officially). That was one of the drivers for a 3090, though I have seen people doing a bit of machining in order to fit the three slot into the rather large enclosure.
Benchmarking
I didn’t take down
Hashcat
Intel NUC i5 + GTX 1060: – example0: 733.3 MH/s, 55s – example400: 2741.0 kH/s – example500: 63348 H/s
Intel NUC i5 + RTX 3090 – example0: 10460.7 MH/s – example400: 10491.0 kH/s – example500: 73839 H/s
Portal 2
Portal 2 runs natively under Linux, so this was an easy test
Intel NUC i5 – no GPU – choppy – barely playable
Intel NUC i5 + GTX 1060: – smooth – playable
Guardians of the Galaxy game
Intel NUC i5 – no GPU – choppy – barely playable
Intel NUC i5 + GTX 1060: – lower framerate while big action is taking place – mostly playable
Intel NUC i5 + RTX 3090 – smooth and with higher settings than the GTX10060 – playable, but CPU runs between 65-85% during gameplay, so an upgrade here would help
Before and After
One of the primary objectives was to lower both the size and power footprint while upgrading the overall capacity and computing experience. As the next couple of pictures show, the first objective was achieved. The second objective remains a bit more elusive. When the system works, it works, but I am still trying to figure out what causes me to land in a reboot cycle where I need to power on and then reboot 2-3 times before the OS fully recognizes the GPU and peripherals connected to the USB hub.
 Image: Full tower on top of network stack
Image: Full tower on top of network stack
And here comes the i7 NUC on top of the eGPU enclosure. NUCs are a study in economy of space, but the following picture really showcases how a full-fledged, highly-performant computer is still about 1/30 the size of the one it replaced (ignoring the GPU, of course).
 Image: Just the enclosure with a NUC on top.
Image: Just the enclosure with a NUC on top.
Moving to the enclosure with the NUC as primary compute, pictured above, Weird that the camera picks up so much debris on the top of the enclosure; it’s actually very new and there is very little dust on top.
Thoughts
While the vertical space savings are significant, I’d say that if space economy is your primary objective, the eGPU only aids in vertical space savings; the enclosure has about the same 2D footprint as my former tower. But, if you count the space (& weight!!) savings in the laptop, it becomes significant. I can comfortably travel with a light, sub-3 lb. (<1.5 kg) laptop in my backpack for hours on end. This is important for conferences like DEFCON or FIRST where you are going to be away from the hotel pretty much all day and want the laptop with you, even though it will be unused in the backpack for much of the time.
After this fairly expensive experiment (which I’m stuck with for a few years), I’m not sure if I’d do it again. There are definitely benefits as I’ve outlined above, and it has mostly met my expectations. The NUC is due for an upgrade in a year, and it’s difficult for me to imagine needing much more in the way of GPU for a while[^1] so I think that will make upgrades easier to navigate. It’s much simpler to look at the small form-factor PCs available and choose from that rather than evaluating all the available parts from a myriad of vendors and navigating their (in)compatibilities.
What it really comes down to is the plug-and-playability. If I could treat this thing like a docking station with a massive GPU, I would be all-in. As it stands, the setup is more of a trial-and-error PnP system where I’m never sure what I’m going to get out of it. To that end, lack of hot plug support is unfortunate. I’d really like to be able to move the eGPU from the NUC to a laptop without needing to shutdown the system.
Since Ubuntu 22.04 and especially 23.04 worked much better than 20.04, I am hopeful for improvements in the ease-of-use.
At a minimum, I would wait for a Thunderbolt 4-capable GPU enclosure. When I started this project, all of the proven enclosures were Thunderbolt 3, manufacturers don’t release these things very often, and I was pretty impatient to give my theory a try. (Also, I’d promised an old, yet capable, system to a friend’s son. I wasn’t about to go back on that deal!). If you try something similar let me know!
[^1]: Unless I decide to go really nuts on traininig language models and other tasks and need to start using some of the Nvidia Tesla gear in my system.
 Image: Original GTX 1060 GPU slotted in the Razer Core X Chroma enclosure
Image: Original GTX 1060 GPU slotted in the Razer Core X Chroma enclosure