兩百萬次光刻、3.5台機器、一個卡住全世界的瓶頸:Dylan Patel 的半導體供應鏈解剖學
260318 SemiAnalysis CEO Dylan Patel 接受訪談,從算力軍備競賽談到 ASML EUV 機台的物理極限,一步步推導出到 2030 年,究竟是什麼東西卡住了人類文明的下一個引擎。
目錄
- 六百億美元的算力焦慮
- Anthropic 的算盤
- GPU 折舊週期的兩種世界觀
- EUV:每顆晶片背後看不見的守門人
- 數學總整理:從 EUV 機台推導全球算力天花板
- 記憶體危機:你的 iPhone 漲價,都是 AI 的錯
- 電力不是瓶頸,但工人可能是
- 中國的平行宇宙
- 機器人、太空算力,與最後的問題
- 最簡單的機器,卡住最複雜的未來
六百億美元的算力焦慮
2025 年,Amazon、Meta、Google、Microsoft 四家公司合計預告的資本支出超過六千億美元。
這個數字換算成電力,接近 50 GW。但沒有人真的認為今年就能用到 50 GW的算力[附註1:為什麼用「GW」來描述算力?]。那麼這些錢究竟花到哪裡去?更奇怪的是,OpenAI 剛宣布募資 1,100 億美元,Anthropic 宣布募資 300 億美元——如果一座 1 GW數據中心的年租金約 130 億美元,那這些實驗室的融資規模,豈不是已經足夠支付今年全年的算力帳單,完全不需要靠收入?
這是訪談一開始,主持人丟給 SemiAnalysis CEO Dylan Patel 的問題。
Patel 的回答,是一堂關於硬體時間尺度的速成課。
大型科技公司的資本支出,很大一部分根本不是花在今年就要上線的東西。以 Google 一千八百億美元的資本支出為例,其中一塊去買了 2028、29 年的渦輪機訂金,一塊去預付了 2027 年的數據中心工程,還有一塊花在電力購買協議的頭期款上。今年美國大約新增二十GW的算力,其中一部分的資本支出,其實是前一年就已付出的。
所以帳是對的,只是時間點不同。
而這一切的最大買主,是 Anthropic 和 OpenAI。
Anthropic 的算盤
Patel 給了一個具體的成長曲線估算。
Anthropic 在過去幾個月的收入走勢:一月增加約 40 美元的 ARR,二月增加約 60 億美元。如果把這條線直接延伸,接下來十個月就會再增加 600 億美元的收入。
600 億美元的收入,按 Anthropic 最近被媒體報導的毛利率換算,意味著大約 400 億美元的算力支出。400 億除以每GW年租金約 100 億美元,得到 4 GW的推算算力需求——僅僅是為了服務新增的推論流量,還沒算上研發和訓練用的算力。
這讓 Patel 得出一個估計:Anthropic 今年年底需要達到 5 GW以上的算力,才能跟上收入增速。
但問題是,Anthropic 的策略一直比 OpenAI 保守。Dario Amodei 公開表示過他不想簽那些「瘋狂的」大型算力合約,不想讓公司走到財務懸崖邊緣。這個決定在短期很理性,但如果收入比預期更快爆炸性成長呢?
結果就是:Anthropic 現在必須在市場上緊急找算力,而那些早就被搶光的優質供應商——Google、Amazon——已先被 OpenAI 用長約鎖定,或是自己保留。Anthropic 不得不轉向更小的雲端供應商、或是接受透過 Bedrock 和 Vertex 等中介平台服務客戶的安排,等於多付一層抽成。
Patel 說,OpenAI 則更積極——不只鎖定 Microsoft、Google、Amazon,還去找 CoreWeave、Oracle、SoftBank Energy,甚至其他更小的供應商。這帶來的後果是:算力量多、議價能力強、不需要在最後一刻補貨。
兩條路,兩種代價。
到年底,Patel 估計 Anthropic 大約可以達到 5 到 6 GW,OpenAI 則會略高一些,兩者在 2027 年應該都會達到 10 GW左右。
GPU 折舊週期的兩種世界觀
訪談中間插入了一個財務界爭論已久的問題:GPU 到底應該按幾年折舊?
著名做空者 Michael Burry 認為頂多三年。他的邏輯是:NVIDIA 每兩年幾乎把效能翻三四倍,如果你用五年折舊,到了第三年,市場上已經有比你手上的機器更便宜三倍的新晶片,你這台舊 H100 的市場租金就從每小時 2 美元跌到 1 美元,甚至 0.7 美元,你的投資報酬就泡湯了。[附註2]
Patel 的反駁是:這個邏輯成立的前提是「新晶片無限供應」。如果你能無限買到 Rubin,那當然 Hopper 就廢了。但問題在於,現在整個產業的半導體產能根本跟不上需求,新晶片的出貨量本身就是受到嚴格限制的。
在半導體嚴重短缺的世界裡,你衡量一台 GPU 的價值,不是拿它去和「理論上可以買到的最新晶片」比,而是問「這台機器今天能幫我賺多少錢」。如果這台 Hopper 每小時能幫你跑出兩美元的推論收入,那它就值這個錢,不管 Rubin 的性能是它的幾倍。
這意味著:GPU 的真實有效壽命,可能遠比市場悲觀者預期的更長。
EUV:每顆晶片背後看不見的守門人
訪談在這裡進入最核心的部分。
Patel 問了一個讓所有宏大算力目標都必須面對的問題:Sam Altman 說他想在 2030 年每週建 1 GW的算力——這在物理上可能嗎?
答案取決於一家總部在荷蘭埃因霍芬的公司,ASML。
ASML 生產全世界最複雜的機器:EUV 光刻機。這台機器是所有先進邏輯晶片(三奈米、二奈米)生產過程中不可或缺的設備。沒有它,就沒有 NVIDIA 的 Hopper 或 Blackwell,也沒有 Apple 的 A 系列晶片。
EUV 機台的工作原理令人瞠目:機器把熔化的錫滴拋出,用雷射精確連擊三次,使錫滴被激發、釋放出 13.5 奈米波長的 EUV 光。這道光通過卡爾蔡司生產的反射鏡組(每組約十八片、以鉬和釕交替沉積而成的多層鏡),照射在塗有光阻的晶圓上,按照設計圖案(光罩)對晶圓表面進行圖形化曝光。整個過程要求所有部件的對準精度達到三奈米甚至更小——而且曝光頭和晶圓平台都在以九倍重力加速度高速相對掃描。
這台機器需要在荷蘭拆解,用多架貨機運到客戶工廠,再在當地重新組裝調試,整個過程耗時數個月。
ASML 今年能生產約七十台,明年約八十台,到 2030 年代,即使積極擴產,也只能到一百台出頭。
為什麼不能更快?
因為 EUV 機台的每一個主要組件,都是極度複雜的獨立供應鏈的終點:光源由 ASML 旗下 Cymer 製造(位於聖地牙哥),鏡片由卡爾蔡司(德國)製造,光罩台由ASML在 Wilton(康乃狄克州)的工廠製造,晶圓台同樣在歐洲生產。
這些供應商沒有決定大幅擴產,因為他們根本不相信 AI 需求會到那個量級。Patel 描述了一個諷刺的困境:整條供應鏈每個環節都把需求預測砍一個折扣,越往下砍越多,最後到了 ASML 的層次,可能已經剩下需求的一半甚至更少。
ASML 是世界上唯一能造這台機器的公司,但它刻意沒有利用這個壟斷地位提價——「他們從未把定價漲幅超過能力的提升幅度」,Patel 如此說。一台 EUV 機台從當初的約一點五億美元,漲到現在的約三到四億美元,但同期機台的晶圓吞吐量和對準精度都已大幅改善,對客戶而言仍然是淨受益。
數學總整理:從 EUV 機台推導全球算力天花板
這一節將訪談中散落在各處的數字集中整理,展示 Patel 如何一步步推導出 2030 年的算力上限。
1 GW算力需要多少 EUV 產能?
以 NVIDIA Rubin 架構(三奈米節點)為例,建立一GW的數據中心算力,需要以下晶圓投入:
| 晶圓類型 | 所需量 | 用途 |
|---|---|---|
| 三奈米邏輯晶圓 | 約 55,000 片 | GPU 邏輯核心 |
| 五奈米晶圓 | 約 6,000 片 | 其他元件 |
| DRAM 記憶體晶圓 | 約 170,000 片 | HBM 記憶體 |
三奈米邏輯晶圓的生產,每片晶圓需要約 70 道光罩曝光步驟,其中約 20 道使用 EUV 曝光(最關鍵也最昂貴的步驟)。
計算過程:
EUV 曝光次數(邏輯)= 55,000 片 x 20 道 EUV = 1,100,000 次
加上 5 奈米及 DRAM 的 EUV 曝光
→ 合計約 2,000,000 次 EUV 曝光通過(per gigawatt)
每台 EUV 機台的吞吐量:
EUV 機台吞吐量 = 75 片晶圓/小時 x 90% 開機率
= 約 67.5 片有效晶圓/小時
每台 EUV 機台年處理量 = 67.5 x 8,760 小時 ≈ 590,000 片/年
因此,每GW算力所需的 EUV 機台數:
EUV 需求 = 2,000,000 次曝光 ÷ (590,000 片/機台/年) ≈ 3.5 台 EUV 機台
結論:建立 1 GW的 AI 算力,約需 3.5 台 EUV 機台的一年產能支撐。
2030 年的 EUV 機台總存量
現有存量(2025):TSMC 等廠合計約 250–300 台
年新增:2025 年約 70 台,2026 年 80 台,到 2030 年增至約 100 台/年
累計至 2030 年底:約 700 台 EUV 機台(含現有存量加新增)
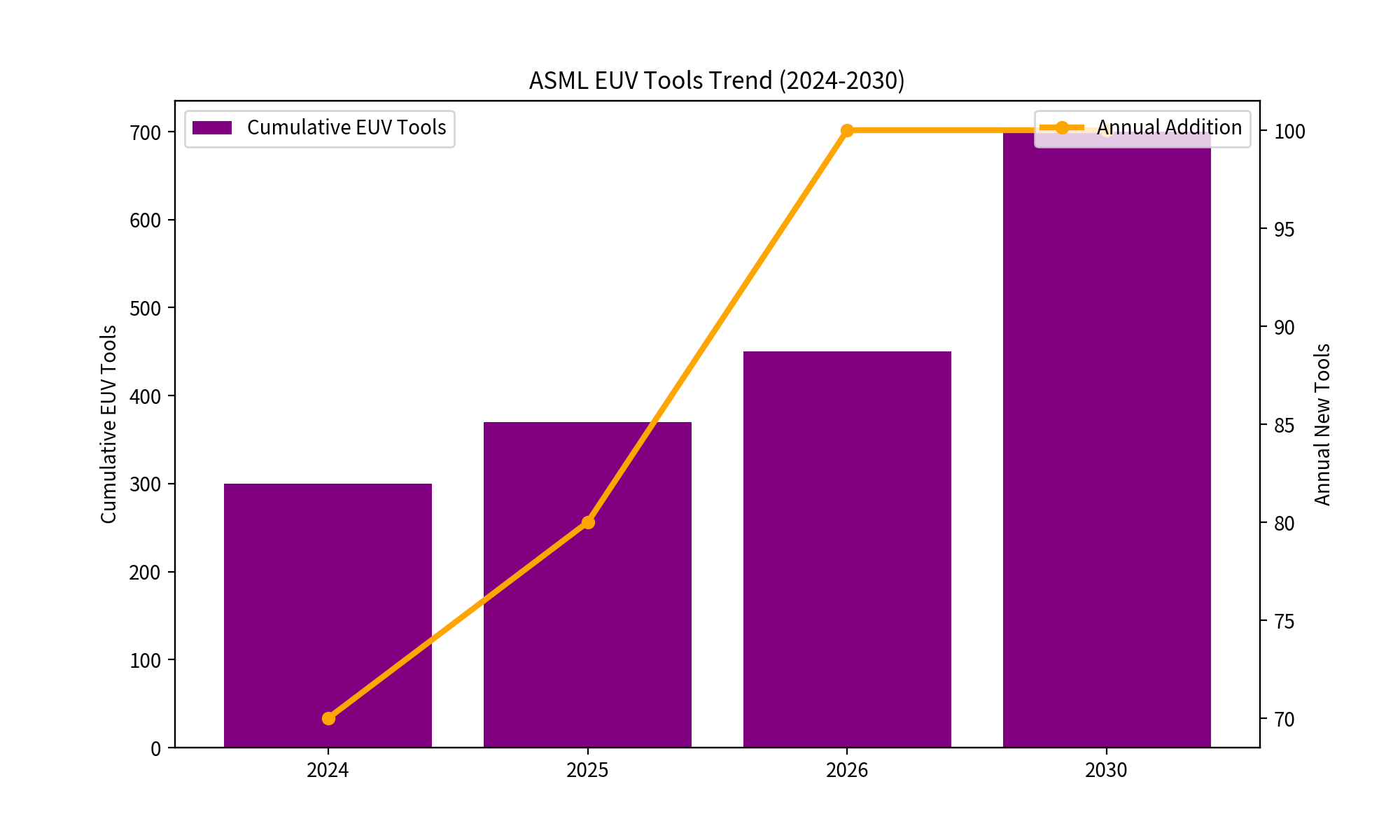
全球 AI 算力天花板
700 台 EUV 機台 ÷ 3.5 台/GW = 200 GW的 AI 算力(全部分配給 AI 的情況下)
但當然,EUV 產能不會百分之百分配給 AI,手機、PC、汽車晶片也需要。
Sam Altman 的目標是否可行?
Sam Altman 曾表示希望在 2030 年達到每週建 1 GW,即每年約 52 GW的新增算力。
52 GW ÷ 200 GW(全球上限)= 26% 的全球 EUV 產能份額
Patel 認為這個數字是合理的,因為今年 NVIDIA 大約就已佔據 TSMC 三奈米產能的相近比例,而且 AI 晶片在整個半導體市場的份額仍在增長。
記憶體的 EUV 乘數效應
HBM(高頻寬記憶體)是 AI 晶片的另一個關鍵瓶頸。HBM 是將 DRAM 晶圓垂直堆疊而成,但每片 HBM 晶圓能產出的記憶體位元數,比一般 DRAM 少三到四倍——因為你把面積花在堆疊結構而非純粹的儲存密度上。
一片 DRAM 晶圓能產出的有效記憶體(作為 HBM 時)= 一片 DRAM 晶圓直接用時的 25–33%
這意味著要滿足 1 GW AI 算力的記憶體需求,需要消耗的 DRAM 晶圓量,比表面上看起來多三到四倍。
2026 年,大型科技公司總算力資本支出約 6,000 億美元,其中約 30% 流向記憶體——即 1,800 億美元。這個比例在歷史上是罕見的高。
HBM vs. DDR:頻寬就是一切
以搭載在 Rubin 架構上的 HBM4 為例:
HBM4 頻寬 = 2,048 bits 介面 x 10 GT/s = 2,048 x 10 ÷ 8 = 2,560 GB/s ≈ 2.5 TB/s(每組)
DDR5(相同晶片邊緣面積)≈ 64–128 bits x 6.4–8 GT/s ÷ 8 = 64–128 GB/s
頻寬差距:約 20–40 倍。
這就是為什麼用普通 DRAM 替換 HBM 在工程上幾乎不可行——GPU 的計算能力會因為等待資料而大量閒置,等於浪費了所有的矽晶片面積。
最終瓶頸的推導
綜合以上分析:
- 電力:有多種替代方案(往復式引擎、燃料電池、太陽能加儲能等),單個類別就能達到數十GW,整體上不是最終瓶頸。
- 數據中心:建設週期短(最快八個月),可模組化,勞動力是限制而非根本瓶頸。
- 邏輯晶片製造(三奈米):受到 EUV 機台年產量上限約束,2030 年約一百台/年,但現有存量累計可支撐 200 GW的上限。
- 記憶體(HBM/DRAM):30% 的算力資本支出、供應緊張、無法輕易用普通 DRAM 替代,是近期最顯著的瓶頸。
- EUV 機台本身:長達 28–29 年的最終瓶頸,因為每個子組件的供應鏈都極度複雜、無法快速擴產,而且整條供應鏈都還未充分「相信」AI 的需求量級。
結論:到 2028–29 年,所有其他瓶頸都會逐步被解決或繞過,但 EUV 機台的生產速度,才是最終決定全球 AI 算力天花板的那個數字。
記憶體危機:你的 iPhone 漲價,都是 AI 的錯
這裡是訪談中最有趣的意外轉折之一。
Patel 提出了一個乍聽反直覺的觀點:AI 算力爆炸,讓你的智慧型手機越來越貴,而且品質越來越差。
邏輯如下。全球 DRAM 的供給是有限的。AI 訓練和推論的需求,尤其是 HBM,正在以驚人的速度增長。而 AI 買家願意支付比手機廠商更高的價格,簽更長的合約,鎖定更多產能。於是 DRAM 廠商的資源配置轉向 AI,消費型 DRAM 的供給收縮,價格上漲。
Patel 的估算非常具體:一支 iPhone 大約需要 12 GB 的記憶體。過去每 GB 成本約三到四美元,現在漲到約十二美元,光是 DRAM 一項的成本就增加了一百美元,再加上 NAND 快閃記憶體同樣漲價,一台 iPhone 的物料成本可能增加一百五十美元。蘋果不會完全自行吸收這個成本,轉嫁後消費者最終多付二百五十美元。
更劇烈的衝擊在中低端手機市場。Patel 引用其在亞洲的分析師數據:小米和 OPPO 等廠商的中低端出貨量,正在被砍到一半,因為這些機型對 DRAM 漲價的承受力遠不如高端旗艦。
SemiAnalysis 的預測是全球智慧型手機年出貨量從 1.4 億台(峰值)跌至今年的 8 億,明後年甚至可能到6億到5億台。
這意味著 AI 不只是在奪走電力和晶圓,也在間接讓消費電子產業走向收縮。Patel 說,這會讓更多人「恨 AI」。
電力不是瓶頸,但工人可能是
訪談花了大量篇幅討論電力,結論卻出乎意料地樂觀——至少和半導體相比。
Patel 的核心論點是:電力的供應鏈,比晶片的供應鏈簡單太多了。
是的,全球只有三家公司能做聯合循環燃氣渦輪機(GE Vernova、三菱、西門子能源),而且某些型號的交貨期已超過 2030 年。但這不是唯一的發電方式。Patel 列舉了至少十六家追蹤中的不同電力設備製造商,包括:航空改裝渦輪(把飛機引擎改成發電機)、中速往復式引擎(類似大型卡車引擎)、船用引擎(Nebious 正在幫微軟的紐澤西數據中心用船用引擎發電)、Bloom Energy 的燃料電池、以及持續下降成本曲線的太陽能加儲能組合。
此外,美國電網目前只為了應對夏天最熱那幾天的尖峰負載而保留大量備用容量。如果裝上足夠的公用事業規模儲能,這些平時閒置的容量就能釋放給數據中心——理論上一口氣解鎖美國電網的 20%,即數百GW。
但勞動力可能是真正的制約。Patel 估算,在德州 Abilene 建設 1.2 GW的數據中心就需要 5,000 名工人在尖峰時期同時施工。擴展到 100 GW,大約需要 40 萬名技術工人。美國目前只有約 80 萬名電氣技師,且並非全都適用於這種工作。
解方包括:從歐洲引進高技能電力工人、推動模組化預製(在亞洲工廠把整個機架組裝好,包含電源和冷卻,再整組運到現場安裝)、以及未來機器人勞動力的加入。
電力,問題有,但都可以用工程手段繞過。晶片,就沒這麼容易了。
中國的平行宇宙
Patel 在訪談中多次回到中國這個話題,態度審慎而非聳動。
他的分析框架是:AI 進展的速度快慢,決定了誰最終勝出。
快速進展的世界裡,美國佔優。OpenAI 和 Anthropic 今年底各自大約有 2 GW算力,明年底達到 10 GW。中國的 AI 實驗室算力增速遠沒有這麼快。更重要的是,一旦這些模型從「給你看整個思維鏈」轉向「直接給你結果、後台黑盒思考」,從美國模型「蒸餾」(distill) 知識到中國模型的難度就會大幅上升。收入複利飛速增長(Anthropic 月增數十億美元 ARR),帶動算力投入持續增長,形成一個美國主導的技術飛輪。
慢速進展的世界裡,情況反轉。中國正在強力推進完整的本土半導體供應鏈,從光刻機到記憶體到邏輯晶片。Patel 估計到 2030 年,中國的 DUV 光刻機本土年產能約達 100 台(相比之下,ASML 的 DUV 年產量仍是數百台)。EUV 方面,中國可能屆時有能用的原型機,但還在「產能地獄」之前。如果 AGI 時間線被推遲到 2035 年,那麼中國有足夠的時間把整條供應鏈垂直整合完成,屆時西方依賴的美日韓台歐洲多國分散供應鏈,反而顯得脆弱。
Patel 也特別點名了 Huawei。這是一家在 AI 時代之前就已擁有完整技術堆疊的公司:頂尖軟體工程師、網路技術(本來是其最大業務)、AI 研究人才、自有晶圓廠,以及自己的終端市場。
他認為,如果 2019 年 Huawei 沒有被禁止使用台積電,Huawei 可能已超越 Apple 成為台積電最大客戶,並持續侵蝕 NVIDIA 的市場。
但那扇門,已經關上了。
機器人、太空算力,與最後的問題
訪談的最後幾個問題,把場景從 2025 年的數據中心,推到了更遙遠的未來。
如果台灣出事,能只搬走工程師嗎?
這是主持人提出的一個戰略問題:如果有一天台灣局勢惡化,能否透過空運所有台積電工程師來保住這些知識?
Patel 的答案是:不夠。
即使你成功把所有工程師撤離,你也必須在某個地方重新蓋廠,重新安裝設備。但EUV 機台本身需要用台灣生產的晶片來製造,而這些晶片又依賴台灣的 EUV 機台 —— 一條吞噬自身尾巴的蛇。
更大的問題是:如果台灣的晶圓廠被摧毀,中國的垂直整合半導體供應鏈,相對於其餘世界反而更強。你在最壞的時間點,把全球增量算力能力從可能的每年數百GW,打回 Intel 加 Samsung 的每年 10 到 20 GW。
人形機器人的算力邏輯
如果 2030 年有數百萬台人形機器人在全球活動,算力怎麼分配?
Patel 認為,最有效率的架構不是讓每台機器人攜帶強大的本地晶片,而是把大量「思考」留在雲端,機器人本地只需要做低延遲的動作執行,由雲端模型每秒或每十分之一秒下達高層指令。
理由有三:雲端可以做批次推算,降低每個 token 的成本;雲端的模型可以更大更強;機器人上的晶片需要低功耗,這和高效能 AI 晶片的需求相衝突,而現在的半導體供應本就不足,如果數百萬台機器人都帶著尖端晶片,就是在和數據中心搶資源。
這意味著一個奇特的未來:即使機器人在物理上分散於世界各地,它們的「智慧」仍高度集中在少數幾個超大型數據中心裡。
最簡單的機器,卡住最複雜的未來
整場訪談讀下來,有一個數字讓人印象深刻:1.2 億美元。
這是 3.5 台 EUV 機台的總售價,是支撐 1 GW AI 算力所需的關鍵設備成本。而 1 GW的數據中心,總資本支出大約 500 億美元。也就是說,500 億美元的算力基礎設施,命懸於 1.2 億美元的工具供應鏈。
更荒謬的是,ASML 的供應鏈有超過一萬個節點。Carl Zeiss 用於鏡片的工人,可能總共不超過一千人。沒有這一千個人做出完美到奈米級精度的鏡片,沒有人能製造 EUV 機台;沒有 EUV 機台,沒有先進邏輯晶片;沒有先進邏輯晶片,沒有下一代 AI。
Patel 沒有說這條鏈會斷。他說的是:它沒有人們想像的那麼有彈性,而且它對自己即將面臨的需求量,認知仍然嚴重滯後。
人類文明最雄心勃勃的技術計畫,正等著一家荷蘭公司每年多交付幾十台機器。
#AI #tech #economics #investment #semiconductor #anthropic
附註一:為什麼用「GW」來描述算力?
讀到這裡,你可能一直有個疑惑:GW(吉瓦)不是電力的單位嗎?一座核電廠大約 1 GW,一台電風扇大約 50 W,1 GW等於同時開著兩千萬台電風扇。這和「算力」有什麼關係?
關係非常直接——因為 GPU 是靠電跑的。
一顆 H100 的功耗約 700 瓦。一個機架通常裝十到二十個伺服器節點,耗電約 10 到 20 千瓦。當一座數據中心能夠穩定供應 1 GW的電力,它就能同時讓數以十萬計的 GPU 全力運算。電力,就是算力的物理上限——冷卻系統、配電設備、散熱管路,全部跟著用電量等比例放大。
所以這個產業索性就用電力換算算力。說「今年新增 20 GW的算力」,意思就是「今年新建的數據中心能額外消耗二百億瓦的電力來跑 AI 模型」。這比說「新增幾十萬張 GPU」更精確,也更容易讓不同廠牌、不同架構的設備有一個共同的比較基準。
那為什麼訪談裡說「今年實際新增約 20 GW」,而不是六千億美元 CapEx 換算出來理論上的 50 GW?
因為 CapEx 不是今年全部花掉的錢,而是今年承諾要花的錢,其中大部分是預付給未來的——2027 年的廠房、2028 年的渦輪機訂金、2029 年的電力合約頭期款。真正在今年接上電、開始跑模型的機器,只有 20 GW。
一個比喻:你用六千億預算訂了一批車,但工廠說今年只能交二十台,其餘的排到後年。你今年實際能開的,就只有這二十台。50 GW是你花的錢,20 GW是你今年真正拿到的算力。
附註二
Burry 的邏輯是:
NVIDIA 大概每兩年推出新一代晶片,效能大約提升三到四倍,但售價只漲一點點或持平。 所以時間軸大概是這樣:
2024 年:H100 是市場最好的選擇,租金每小時 2 美元,合理。 2026 年:Blackwell 上市,效能是 H100 的三到四倍,但價格差不多。AI 公司開始問:我為什麼要租舊的 H100?除非你降價。於是 H100 的市場租金從 2 美元跌到大約 1 美元。 2027 年:Rubin 上市,又是三到四倍效能。H100 繼續貶值,租金跌到 0.7 美元。
但你的持有成本還是每小時 1.40 美元,因為這是你當初買入時就鎖定的。 租金 0.7 美元,成本 1.40 美元,每跑一小時就虧 0.7 美元。 這就是 Burry 說「折舊週期應該是三年不是五年」的意思——到了第三年,這台機器在市場上已經不值這個錢了,你當初的投資假設已經破功。
本文整理自主持人對 SemiAnalysis CEO Dylan Patel 的訪談。SemiAnalysis 是目前最受業界重視的半導體產業研究機構之一,追蹤全球每一座數據中心、每一座晶圓廠、以及每一筆關鍵設備訂單。

凡是能解釋「為什麼」的事,我都著迷。科學、創新、哲學、投資,本質上是同一件事:找出規律,然後解開。
讀到真正新奇的東西,會興奮到發抖。
不在書桌前的時候,就在山上、水裡、或某個還沒搭營地的空地。
contact via teamtaiwan.trophy127@passmail.net 本站僅提供參考,不是人生建議,不是醫療建議,不是投資建議。